"The woman is created for a man, not a man for a woman" - such a postulate ...


The first, the most natural step of probabilistic reasoning is as follows: If you have some variable that takes values \u200b\u200brandomly, then you would like to know with which probabilities this variable takes certain values. The combination of these probabilities is just asks the distribution of probabilities. For example, having a playing bone, you can A priori assume that with equal probabilities of 1/6, it will fall on any face. And this happens, provided that the bone is symmetrical. If the bone is asymmetric, then you can determine the greatest probabilities for those faces that fall out more often, and smaller probabilities - for the faces that fall less frequently, based on experienced data. If some line does not fall out at all, then it can be assigned a probability of 0. This is the simplest probability law, with which you can describe the results of throwing bones. Of course, this is an extremely simple example, but similar tasks arise, for example, with actuarial calculations, when a real risk is calculated on the basis of real data when issuing an insurance policy.
In this chapter, we will consider probabilistic laws that are most often arising in practice.
The graphs of these distributions can be easily built in Statistica.
Normal distribution
Normal probability distribution is particularly often used in statistics. Normal distribution gives good model For real phenomena, in which:
1) There is a strong trend of data to be grouped around the center;
2) positive and negative deviations from the center are equally well;
3) the frequency of deviations quickly falls when the deviations from the center become large.
The mechanism underlying the normal distribution explained by the so-called central limit theorem can be figuratively described as follows. Imagine that you have particles of floral pollen, which you randomly threw into a glass of water. Considering a separate particle under a microscope, you will see an amazing phenomenon - a particle moves. Of course, this happens because water molecules move and transmit its movement of suspended pollen.
But how exactly is the movement? Here's more interest Ask. And this movement is very fad!
There is an infinite number of independent effects on a separate particle of pollen in the form of blows of water molecules, which cause a particle to move along a very strange trajectory. Under the microscope, this movement reminds many times and chaotic broken line. These freshers cannot be predicted, there are no regularity in them, which is exactly the chaotic blows of molecules about a particle. A suspended particle, having experienced the blow of the water molecule at a random point of time, changes the direction of its movement, then somewhat moving on inertia, then again falls under the bottom of the next molecule and so on. There is an amazing billiards in a glass of water!
Since the movement of molecules has a random direction and speed, the magnitude and direction of the trajectories of the trajectory are also completely random and unpredictable. This is an amazing phenomenon called Brownian movement, opened in the XIX century, makes us think about much.
If you enter the appropriate system and mark the coordinates of the particles through some points in time, then just get a normal law. More accurately, the displacements of the pollen particles arising from the blows of molecules will obey the normal law.
For the first time, the law of movement of such a particle called Brownian, at the physical level of strictness was described by A. Einstein. Then a simpler and intuitive approach developed Lenhevian.
Mathematics in the 20th century dedicated to this theory the best pages, and the first step was made 300 years ago, when it was opened the simplest option central limit theorem.
In the theory of probability, the central limit theorem, originally known in the formulation of Moava and Laplace in the XVII century as the development of the famous law of large numbers Y. Bernoulli (1654-1705) (see J. Bernoulli (1713), ARS Conjectandi), are currently extremely developed and reached its heights. in modern principle Invariance, in the creation of which the Russian Mathematical School played a significant role. It is in this principle that the Mathematical explanation of the Brownian particle moves its strictly.
The idea is that when summing a large number of independent values \u200b\u200b(molecules blows about pollen particles) in certain reasonable conditions Operately distributed values \u200b\u200bare obtained. And this happens independently, that is, invariant, from the distribution of initial values. In other words, if a variable is affected by many factors, these effects are independent, relatively small and are composed with each other, then the value obtained as a result has a normal distribution.
For example, a practically infinite number of factors determine human weight (thousands of genes, predisposition, disease, etc.). Thus, we can expect a normal weight distribution in the population of all people.
If you are a financier and engage in the game of the stock exchange, then, of course, you are known when the campaigns of shares behave like Brownian particles, experiencing chaotic blows of many factors.
Formally the density of the normal distribution is written as follows:

where A and õ 2 are the parameters of the law, interpreted according to the mean value and the dispersion of this random variable (due to the special role of normal distribution, we will use a special symbolism to refer to its density function and distribution function). Visually a chart of normal density is a famous bell-shaped curve.
The corresponding function of the distribution of a normal random variable (A, õ 2) is denoted by f (x; A, õ 2) and is given by the relation:

Normal law with parameters A \u003d 0 and õ 2 \u003d 1 is called standard.
Reverse function of standard normal distribution applied to Z, 0 Take advantage of the probabilistic Calculator Statistica to calculate Z and vice versa. The main characteristics of the Normal Law: Mean, fashion, median: e \u003d x mod \u003d x med \u003d a; Dispersion: d \u003d õ 2; Asmetry: Excess: From the formulas it can be seen that the normal distribution is described by two parameters: a - mean - average; õ - Stantard Deviation - standard deviation, read: "Sigma". Sometimes S. dartan deviation is called rms deviationBut this is already outdated terminology. We present some useful facts regarding normal distribution. The average value determines the measure of density. The density of the normal distribution is symmetric relative to the average. The average normal distribution coincides with the median and fashion (see graphics). Density of normal distribution with dispersion 1 and medium 1 Density of normal distribution with average 0 and dispersion 0.01 Density of normal distribution with average 0 and dispersion 4 With an increase in the dispersion, the density of the normal distribution is blown or spreads along the axis OH, with a decrease in the dispersion, it, on the contrary, is compressed, concentrating around one point - the maximum value that coincides with the average value. In the limiting case of zero dispersion random value degenerates and takes the only value equal to the average. It is useful to know the rules of 2- and 3 sigma, or 2- and 3-standard deviations that are associated with normal distribution and are used in a variety of applications. The meaning of these rules is very simple. If from the point of medium or, which is the same, from the point of the maximum of the density of the normal distribution to postpone the right and left, respectively, two and three standard deviations (2- and 3 sigma), then the area under the chart of normal density, calculated by this gap, will be, respectively equal to 95.45% and 99.73% of the total area under the schedule (check on the probabilistic Calculator Statistica!). In other words, this can be expressed as follows: 95.45% and 99.73% of all independent observations from a normal set, such as the size of the part or stock price, lies in the zone of 2- and 3-standard deviations from the average value. Uniform distribution Uniform distribution is useful when describing variables, in which each value is equally, in other words, the values \u200b\u200bof the variable are evenly distributed in some region. Below are the density formulas and the distribution functions of a uniform random variable that takes the values \u200b\u200bon the segment [A, B]. Of these formulas, it is easy to understand that the likelihood that a uniform random value will take values \u200b\u200bfrom a set [C, D] [A, B], equal to (D - C) / (B - a). Put a \u003d 0, b \u003d 1. Below is a graph of a uniform probability density concentrated on the segment. Numerical characteristics of uniform law: Exponential distribution There are events that can be called rare on an ordinary language. If T is the time between the onset of rare events occurring on average with an X intensity, then the value This distribution has a very interesting property of the lack of amersion, or, as they say, Markov's property, in honor of the famous Russian Mathematics Markova A. A., which can be explained as follows. If the distribution between the moments of the onset of some events is indicative, then the distribution countdown from any moment t until the next event, also has an indicative distribution (with the same parameter). In other words, for the flux of rare events, the next visitor's waiting time is always distributed significantly regardless of how much time you waited for it. The indicative distribution is associated with Poisson distribution: in a single time interval, the number of events, the intervals between which are independent and are indicatively distributed, has the distribution of Poisson. If the intervals between visits of the site have an exponential distribution, then the number of visits, for example, within an hour, is distributed under the law of Poisson. The indicative distribution is a special case of Waibulla distribution. If the time is not continuous, but discretely, the analogue of the indicative distribution is the geometric distribution. The density of the exponential distribution is described by the formula: This distribution has only one parameter, which determines its characteristics. The density schedule of the indicative distribution is: The main numerical characteristics of the exponential distribution: Erlang distribution This continuous distribution is concentrated on (0.1) and has a density: Mathematical expectation and dispersion are equal, respectively Erlang distribution is named after A. Erland (A. Erlang), first applied it in the tasks of the theory of mass maintenance and telephony. Erlan's distribution with parameters μ and n is the distribution of the amount of the amount of independent, equally distributed random variables, each of which has a demonstrative distribution with the parameter Nμ For N \u003d 1 The distribution of Erland coincides with an indicative or exponential distribution. Laplace distribution The density function of the Laplace distribution, or, is also called, double exponential, used, for example, to describe the distribution of errors in regression models. Looking at the schedule of this distribution, you will see that it consists of two exponential distributions, symmetrical about the OY axis. If the position parameter is 0, then the density function of the Laplace distribution has the form: The main numerical characteristics of this distribution law under the assumption that the position parameter is zero, look like this: In the general case, the density of the distribution of Laplace has the form: a - average distribution; b - scale parameter; E is the number of Euler (2.71 ...). Gamma distribution The density of the exponential distribution has a fashion at point 0, and it is sometimes uncomfortable for practical applications. In many examples, it is known in advance that the fashion under consideration of the random variable is not equal to 0, for example, the intervals between the parishes of buyers in the e-commerce store or entering the site have a pronounced fashion. To simulate such events, a gamma distribution is used. The density of the gamma distribution is: where r - Mr. Euler, A\u003e 0 - the "Form" parameter and b\u003e 0 - the scale parameter. In the particular case, we have the distribution of Erland and exponential distribution. The main characteristics of gamma distribution: Below are two graphs of the gamma distribution density with a scale parameter of 1, and the form parameters equal to 3 and 5. The useful property of the gamma distribution: the sum of any number of independent gamma-distributed random variables (with the same scale parameter B) (A l, b) + (a 2, b) + --- + (a n, b) is also subject to gamma distribution, but with parameters A 1 + A 2 + + A N and B. Salmonormal distribution The random value H is called logarithmically normal, or logon, if its natural logarithm (LNH) is subordinated to the normal distribution law. The logon distribution is used, for example, when modeling of variables such as income, newlywed age or permissible deviation from the standard harmful substances In food. So, if the value x has a normal distribution, then the value y \u003d e x has a logon distribution. If you substitute the normal amount into the degree of exhibitors, you will easily understand that the loggnormal value is obtained as a result of multiple multiplications of independent values, as well as a normal random value is the result of multiple summation. The density of the carrier distribution has the form: The main characteristics of the logarithmically normal distribution: Chi-square distribution The sum of squares t independent normal quantities Middle 0 and dispersion 1 has a chi-square distribution with t degrees of freedom. This distribution is most often used when analyzing data. Formally, the density of the Yam-Square distribution with t degrees of freedom has the form: With negative x Density refers to 0. The main numerical characteristics of hee -Kvadrat distribution: The density schedule is shown in the figure below: Binomial distribution The binomial distribution is the most important discrete distribution that is concentrated only at several points. These points binomial distribution attributes positive probabilities. Thus, the binomial distribution differs from continuous distributions (normal, chi-square, etc.), which attribute zero probabilities separately selected points and are called continuous. It is better to understand the binomial distribution by considering the next game. Imagine you throw a coin. Let the probability of the emission of the coat of arms r, and the probability of the fallout of the rush is Q \u003d 1 - P (we consider the most common case when the coin is asymmetrical, has, for example, a displaced center of gravity-in the coin is made of a hole). The deposition of the coat of arms is considered to be successful, and the loss of the ripe - failure. Then the number of empty coat of arms (or switches) has a binomial distribution. Note that the consideration of asymmetric coins or incorrect playing bones is of practical interest. As J. Neumann noted in his elegant book "The introductory course of probability theory and mathematical statistics"People have long guessed that the frequency of points of points on the playing bone depends on the properties of this bone itself and can be artificially changed. Archaeologists found two pairs of bones in the tomb of Pharaoh: "honest" - with equal probabilities of loss of all the faces, and fake - with an intentional displacement of the center of gravity, which increased the likelihood of six. The parameters of the binomial distribution are the probability of success P (Q \u003d 1 - P) and the number of tests p. Binomial distribution is useful for describing the distribution of binomial events, such as the number of men and women in randomly selected companies. Of particular importance is to use the binomial distribution in game tasks. Accurate formula for the probability of success in n tests are written as follows: p-chance of success q is 1-p, q\u003e \u003d 0, p + q \u003d\u003d 1 n- The number of tests, m \u003d 0.1 ... m The main characteristics of the binomine distribution: Schedule of this distribution when various number Tests P and probabilities of success P has the form: The binomial distribution is associated with the normal distribution and distribution of Poisson (see below); at certain values \u200b\u200bof the parameters when big number Tests it turns into these distributions. It is easy to demonstrate using Statistica. For example, considering a binomial distribution schedule with parameters p \u003d 0,7, n \u003d 100 (see Figure), we used Statistica Basic - you can notice that the schedule is very similar to the density of the normal distribution (so it really is!). Binomial distribution schedule with parameters P \u003d 0.05, n \u003d 100 is very similar to the Poisson distribution schedule. As already mentioned, the binomial distribution arose from observations of the simplest gaming game - throwing the right coin. In many situations, this model serves as a good first approach for more complex games and random processes arising when playing the stock exchange. It is wonderful that the essential features of many complex processes It can be understood based on a simple binomial model. For example, consider the following situation. We note the deposition of the coat of arms as 1, and the loss of the rush is minus 1 and summarize the winnings and losses into sequential moments of time. The graphs show the typical trajectories of such a game at 1,000 shots, at 5,000 shots and at 10,000 shots. Note what long time passes the trajectory is higher or lower than zero, in other words, the time during which one of the players is in winning in an absolutely fair game, very long, and transitions from winning a loss is relatively rare, and it hardly stacked In an unprepared consciousness, for which the expression "absolutely fair game" sounds like a magic spell. So, although the game and is valid under the conditions, the behavior of the typical trajectory is not at all fairly and does not demonstrate equilibrium! Of course, empirically this fact is known to all players, a strategy is connected with him when the player does not give to get away with winnings, and make you play further. Consider the number of throws during which one player is in winning (trajectory above 0), and the second is in the loss (trajectory below 0). At first glance it seems that the number of such throws is approximately the same. However (see the exciting book: Feller V. "Introduction to the theory of probabilities and its applications." Moscow: Peace, 1984, p.106) at 10,000 shots of perfect coins (that is, for Bernoulli tests with p \u003d Q \u003d 0.5, n \u003d 10 000) The likelihood that one of the parties will lead through over 9,930 tests, and the second is less than 70, exceeds 0.1. It is surprising that in a game consisting of 10,000 challenges of the right coin, the likelihood that leadership will change no more than 8 times, exceeds 0.14, and the likelihood of more than 78 changes in leadership is approximately equal to 0.12. So, we have a paradoxical situation: in the symmetric wandering of Bernoulli "Waves" on the chart between consistent returns to zero (see graphics) can be strikingly long. This is connected with another circumstance, namely what is for T N / N (the share of time when the graph is above the abscissa axis) the least probable are the values \u200b\u200bclose to 1/2. Mathematics was opened the so-called Act of Arksinus, according to which each time 0< а <1 вероятность неравенства
, где Т n - число шагов, в течение которых первый игрок находится в выигрыше, стремится к Distribution of Arksinus. This continuous distribution is concentrated on the interval (0, 1) and has a density: The distribution of Arksinus is associated with a random wandering. This distribution of the share of time during which the first player is in winning when throwing a symmetric coin, that is, coins that with equal probabilities S falls on the coat of arms and the decision. In a different way, such a game can be viewed as a random wandering of a particle, which, starting from zero, with equal probabilities makes single jumps to the right or left. Since the jumps of the particles - the decay of the coat of arms or the ripe are equally called, then such a wandering is often called symmetric. If probabilities were different, then we would have asymmetrical wandering. The arxinus distribution density schedule is shown in the following figure: The most interesting is the quality interpretation of the graph, from which you can make amazing conclusions about the series of winnings and losses in a fair game. Looking at the schedule, you may notice that the minimum of density is at the point 1/2. "So what?!" - you ask. But if you think about this observation, then your surprise will not be borders! It turns out that defined as a fair, the game is actually not at all as fair as it may seem at first glance. The trajectories of a symmetric random, in which the particle is equal to the time on both positive and on the negative semi-axis, that is, the right or left of the scratch is just the least likely. Turning to the language of the players, it can be said that when throwing a symmetric coin of the game, in which players are equal to the winning and loss, the least is likely. On the contrary, games in which one player is much more likely in winning, and the other respectively in the loss, are the most likely. Amazing paradox! To calculate the likelihood that the share of time t, during which the first player is in winning, lies within T1 BE T2, you need from the value of the distribution function F (T2) subtract the value of the distribution function F (T1). Formally get: P (T1. Relying on this fact can be calculated using Statistic, that at 10,000 steps of the particle remains on the positive side of more than 9930 moments of time with a probability of 0.1, that is, roughly speaking, this provision will be observed at least in one case out of ten (Although, at first glance, it seems absurd; see a wonderful for clarity by Yu. V. Prokhorov "Wandering Bernoulli" in the encyclopedia "Probability and Mathematical Statistics", p. 42-43, M.: Large Russian Encyclopedia, 1999) . Negative binomial distribution This is a discrete distribution that attributes to the whole points. k \u003d 0,1,2, ... probabilities: p k \u003d p (x \u003d k) \u003d c k r + k-1 p r (l-p) k ", where 0<р<1,r>0.
A negative binomial distribution is found in many applications. In general R\u003e 0 The negative binomial distribution is interpreted as the distribution of the waiting time of the R-th "success" in the Bernoulli test scheme with the likelihood of "success" P, for example, the number of shots that need to be made to the second elevation of the coat of arms, in this case it is sometimes called the distribution of Pascal and is a discrete analogue of gamma distribution. For R \u003d 1 The negative binomial distribution coincides with the geometric distribution. If y is a random value having the distribution of Poisson with a random parameter, which, in turn, has a gamma distribution with density It will lose to have a negative binomial distribution with parameters; Poisson distribution Poisson's distribution is sometimes called the distribution of rare events. Examples of variables distributed by the law of Poisson can be: the number of accidents, the number of defects in the production process, etc. The distribution of Poisson is determined by the formula: The main characteristics of the Poisson random variable: The distribution of Poisson is associated with an indicative distribution and with the distribution of Bernoulli. If the number of events has the distribution of Poisson, the intervals between events have an exponential or indicative distribution. Poisson distribution schedule: Compare the Poisson distribution chart with parameter 5 with the Bernoulli distribution schedule at p \u003d q \u003d 0.5, n \u003d 100. You will see that graphics are very similar. In general, there is the following pattern (see for example, an excellent book: Shiryaev A. N. "Probability". Moscow: Science, p. 76): If the tests of Bernoulli N takes big values, and the likelihood of success /? Relatively small, so the average of success (work and na) and is not small and not large, then the distribution of Bernoulli with the parameters N, p can be replaced by the Poisson distribution with the parameter \u003d NP. Poisson's distribution is widely used in practice, for example, in quality control cards as the distribution of rare events. As another example, consider the following task associated with telephone lines and taken from practice (see: Feller V. Introduction to the theory of probabilities and its applications. Moscow: Peace, 1984, p. 205, as well as Molina E. S. (1935 ) PROBABILITY IN ENGINEERING, ELECTRICAL ENGINEERING, 54, P. 423-427; Bell Telephone System Technical Publications Monograph B-854). This task is easy to translate into a modern language, for example, a mobile language language, which is invited to make interested readers. The task is formulated as follows. Let there be two telephone stations - A and V. Telephone station A should provide a connection of 2,000 subscribers with a station B. Quality of communication should be such that only 1 call from 100 waited when the line is released. It is asked: how much do you need to hold phone lines to provide the specified communication quality? Obviously, it is silly to create 2,000 lines, as many of them will be free for a long time. From intuitive considerations it is clear that, apparently, there is some optimal number of lines N. How to calculate this number? Let's start with a realistic model that describes the intensity of the subscriber's appeal to the network, while noting that the accuracy of the model, of course, can be checked using standard statistical criteria. So, suppose every subscriber uses a line on average 2 minutes per hour and connecting subscribers independent (however, as Feller comes rightly, the latter occurs if some events affect all subscribers, such as war or hurricane). Then we have 2000 tests of Bernoulli (coins throws) or network connections with the probability of success P \u003d 2/60 \u003d 1/30. It is necessary to find such n when the probability that more N users are simultaneously connected to the network, does not exceed 0.01. These calculations can be easily solved in the Statistica system. Solving the task on Statistica. Step 1. Open the module Main statistics. Create a binoml.sta file containing 110 observations. Name the first variable BINOMIAL, the second variable - Poisson. Step 2. BINOMIAL, Open the window Variable 1. (See Fig.). Enter the formula in the window, as shown in the figure. Press the button OK. Step 3. Double-clicking on the header Poisson, Open the window Variable 2. (See Fig.) Enter the formula in the window, as shown in the figure. Note that we calculate the Poisson distribution parameter by the formula \u003d n × p. Therefore \u003d 2000 × 1/30. Press the button OK.
Statistica will calculate the probabilities and record them in the created file. Step 4. Scroll to the table to observations with number 86. You will see that the likelihood that over an hour from 2000 network users are simultaneously operating 86 or more, equal to 0.01347, if the binomial distribution is used. The likelihood that within an hour from 2000 network users simultaneously operates 86 or more people, equal to 0.01293, if the Poisson approximation for the binomial distribution is used. Since we need a chance of not more than 0.01, then 87 lines will be enough to ensure the desired communication quality. Close results can be obtained if you use a normal approximation for binomial distribution (check it out!). Note that V. Feller did not have at its disposal the system Statistica and used tables for the binomial and normal distribution. With the help of the same arguments, it is possible to solve the following task discussed by V. Feller. It is required to check, more or less lines will be required to reliably maintain users when splitting them into 2 groups of 1000 people each. It turns out that when dividing users to groups will require additional 10 lines to achieve the quality of the same level. You can also take into account the change in the intensity of the connection to the network during the day. Geometric distribution If independent tests of Bernoulli are conducted and the number of tests is calculated before the onset of the following "success", then this number has a geometric distribution. Thus, if you throw a coin, the number of thumbs up, which you need to do before the fallout of the next coat of arms, is subject to a geometric law. The geometric distribution is determined by the formula: F (x) \u003d p (1-p) x-1 p - probability of success, x \u003d 1, 2.3 ... The name of the distribution is associated with geometric progress. So, the geometric distribution sets the likelihood that success has occurred at a certain step. The geometric distribution is a discrete analogue of the indicative distribution. If the time is changed by quanta, then the probability of success at each moment of time is described by geometrical law. If time is continuous, then the probability is described by an indicative or exponential law. Hypergeometric distribution This is a discrete distribution of probabilities of a random value of X, receiving integer values \u200b\u200bT \u003d 0, 1.2, ..., N with probabilities: where n, m and n are whole non-negative numbers and m<
N, n < N. The hypergeometric distribution is usually associated with a choice without return and determines, for example, the probability of finding exactly black balls in a random sample of the volume N from the general population containing n balls, among which M black and N - white (see, for example, the encyclopedia " and mathematical statistics ", M.: Large Russian Encyclopedia, p. 144). The mathematical expectation of the hypergeometric distribution does not depend on n and coincides with the mathematical expectation μ \u003d np of the corresponding binomial distribution. Dispersion of hypergeometric distribution This distribution is extremely often arising in the tasks associated with quality control. Polynomial distribution Polynomial, or multinomial, distribution naturally summarizes the distribution. If the binomial distribution occurs when throwing a coin with two outcomes (grille or coat of arms), then the polynomial distribution occurs when the playing bone rushes and there are more than two possible outcomes. Formally - this is a joint distribution of probabilities of random variables x 1, ..., x k, taking whole non-negative values \u200b\u200bof N 1, ..., n k, satisfying the condition N 1 + ... + n k \u003d n, with probabilities: The name "polynomial distribution" is explained by the fact that multinomial probabilities occur during the decomposition of the polynomial (p 1 + ... + p k) n Beta distribution Beta distribution has a density of the form: Standard beta distribution is concentrated on a segment from 0 to 1. Using linear transformations, a beta value can be converted so that it will take values \u200b\u200bat any interval. The main numerical characteristics of the value having a beta distribution: Distribution of extreme values The distribution of extreme values \u200b\u200b(type I) has a density of the form: This distribution is sometimes also called the distribution of extreme values. The distribution of extreme values \u200b\u200bis used in modeling extreme events, such as flooding levels, vortex rates, maximum securities market indices for this year, etc. This distribution is used in the theory of reliability, for example, to describe the time of refusal of electrical circuits, as well as in actuarial calculations. Rayleigh distribution The distribution of the relay has a density of the form: where b is a scale parameter. The distribution of the relay is concentrated in the interval from 0 to infinity. Instead of a value of 0 statistica, it allows you to enter a different value of the threshold parameter, which will be deducted from the source data before fitting the distribution of the relay. Consequently, the value of the threshold parameter should be less than all observed values. If two variables in 1 and in 2 are independent of each other and are normally distributed with the same dispersion, then the variable The distribution of the relay is used, for example, in the theory of firing. Waibulla distribution Waibulla's distribution is named after the Swedish researcher Valoddi Weibulla (Waloddi Weibull), which used this distribution to describe the time of failures of different types in reliability theory. Formally the density of the Waibulla distribution is recorded as: Sometimes Waibulla distribution density is also written in the form: B - scale parameter; C - form parameter; E - Euler Constant (2,718 ...). Position parameter. Usually, the distribution of Weibulla is concentrated on semi-axes from 0 to infinity. If instead of the border 0 to enter the parameter A, which is often necessary in practice, then the so-called three-parameter distribution of Weibulla arises. Waibulla's distribution is intensively used in the theory of reliability and insurance. As described above, the exponential distribution is often used as a model that estimates the time of operation to failure as an assumption that the probability of the failure of the object is constant. If the probability of failure changes over time, the distribution of Weibulla is applied. For C \u003d 1 or, in another parametrization, with the distribution of Weibulla, how to see it easily from the formula, transforms into an exponential distribution, and when - in the distribution of the relay. Special methods for evaluating the parameters of the Waibulla distribution parameters are developed (see For example, a book: Lawless for Lifetime Data, Belmont, CA: Lifetime Learning, where the evaluation methods are described, as well as problems arising when estimating the position parameter for three-parameter distribution Weibulla). Often, when analyzing reliability it is necessary to consider the likelihood of refusal for a small time interval after the time t provided that until the moment T Failure did not happen. This function is called the risk function, or the failure intensity function, and is formally determined as follows: H (t) - failure intensity function or risk function at T; f (t) - the density of the distribution of times of failures; F (T) - the distribution function of the failures (integral from the density by interval). In general, the failure intensity function is written as follows: When the risk function is equal to the constant, which corresponds to the normal operation of the device (see formulas). With the risk function, it decreases, which corresponds to the acquisition of the device. When the risk function decreases, which corresponds to the aging of the device. Typical risk functions are shown in the graph. Below are the graphs of the density of the Waibulla distribution with different parameters. You need to pay attention to three areas of the values \u200b\u200bof the parameter A: In the first area, the risk function decreases (setting period), in the second region, the risk function is equal to constant, in the third region the risk function increases. You will easily understand what is said on the example of buying a new car: at the beginning there is a period of adaptation of the machine, then a long period of normal operation, then the car details are wear out and the risk function of its failure increases sharply. It is important that all periods of operation can be described by the same distribution family. This is the idea of \u200b\u200bWaibulla distribution. We present the main numerical characteristics of the Waibulla distribution. Pareto distribution In various tasks of applied statistics, the so-called truncated distributions are quite common. For example, this distribution is used in insurance or taxation, when interest is of interest to income that exceed some value C 0 The main numerical characteristics of the Pareto distribution: Logistic distribution The logistics distribution has a density function: A - position parameter; B - scale parameter; E is the number of Euler (2.71 ...). Wishligh T 2-distribution This is a continuous distribution, focused on the interval (0, g), has a density: where parameters n and K, N\u003e _K\u003e _1 are called degrees of freedom. For k \u003d 1 Watering P-distribution is reduced to the distribution of Student, and at any K\u003e 1 can be considered as a generalization of Student's distribution to a multidimensional case. Distribution of Wishliga is based on the normal distribution. Let the k-dimensional random vector Y have a normal distribution with a zero vector of medium and covariance matrix. Consider the quantity where the random vectors z i are independent among themselves and y and distributed as well as Y. Then the random value of T 2 \u003d y T S -1 y has T 2-distribution of the mallaign with N degrees of freedom (Y - vector-column, T - transposition operator). where a random value t n has the distribution of Student with N degrees of freedom (see "Probability and Mathematical Statistics", Encyclopedia, p. 792). If y has a normal distribution with non-zero average, then the corresponding distribution is called noncentral Wineleng T 2-distribution with N degrees of freedom and the parameter of non-centrality V. Wineling T 2-distribution is used in mathematical statistics in the same situation as the ^ distribution of Student, but only in a multidimensional case. If the results of the observations of X 1, ..., x n are independent, normally distributed random vectors with a medium μ vector and a non-degenerate covariance matrix, then statistics has the Wishligh T 2-distribution with n - 1 degrees of freedom. This fact is based on the Wishligh criterion. In Statistica, the Welling criterion is available, for example, in the module basic statistics and tables (see the dialog box below). Distribution of Maxwell The distribution of Maxwell arose in physics when describing the speed distribution of the molecules of the ideal gas. This continuous distribution is concentrated on (0,) and has a density: The distribution function is: where f (x) is the function of standard normal distribution. Maxwell's distribution has a positive asymmetry coefficient and a single fashion at the point (that is, the distribution is varying). The distribution of Maxwell has the end moments of any order; mathematical expectation and dispersion are equal according to and The distribution of Maxwell is naturally associated with a normal distribution. If x 1, x 2, x 3 are independent random variables that have a normal distribution with parameters 0 and õ 2, then a random variable Cauchy distribution This amazing distribution sometimes does not have an average meaning, since the density of it very slowly tends to zero with increasing x in absolute value. Such distributions are called heavy-tailed distributions. If you need to come up with a distribution that does not have an average, then immediately call the Cauchy distribution. The distribution of Cauchy is vastly and symmetrically relative to the fashion, which is simultaneously median, and has a function of the density of the form: where C\u003e 0 - scale parameter and A - the parameter of the center that determines the modes and medians simultaneously. The density integral, i.e., the distribution function is given by the ratio: Student distribution English statistics V. Gosset, known under the pseudonym "Student" and began his career from a statistical study of the quality of English beer, received the following result in 1908. Let be x 0, x 1, .., x M - independent, (0, s 2) - normally distributed random variables: This distribution, known now as Student's distribution (is briefly designated as t (M) -distribution, where t, the number of freedom degrees), underlies the famous T-criterion designed to compare the average two sets. Density function f t (x) does not depend on the dispersion of õ 2 of random variables and, in addition, is a void and symmetric relative to the point x \u003d 0. The main numerical characteristics of Student distribution: t-distribution is important in cases where the estimates of the average and unknown sample dispersion are considered. In this case, use selective dispersion and T-distribution. At large degrees of freedom (large 30), the T-distribution practically coincides with the standard normal distribution. The graph of the T-distribution density function is deformed by increasing the number of degrees of freedom as follows: the peak increases, the tails are more cool to 0, and it seems that the graphs of the T-distribution density function is compressed from the sides. F-distribution Consider m 1 + m 2 independent and (0, S 2) normally distributed values Obviously, the same random value can also be defined as the ratio of two independent and appropriately normalized chi-square-distributed values \u200b\u200band, that is, The famous English statistics R. Fisher in 1924 showed that the probability density of the random variable F (M 1, M 2) is set by the function: where g (y) is the value of the Gamma function of Euler in. point y, and the law itself is called F-PAC determination with the numbers of degrees of freedom of the numerator and the denominator, equal to the T, 1l T7 The main numeric characteristics of the F distribution: F-distribution occurs in discriminant, regression and dispersion analysis, as well as in other types of multidimensional data analysis. Random event- This is any fact that the test may occur or not happen. Random event is the test result. Test- This is an experiment, performing a certain set of conditions in which this or that phenomenon is observed, one or another result is recorded. Events are indicated by the capital letters of the Latin alphabet A, B, p. Numerical measure of the degree of objectivity The possibility of an occurrence of an event is called the probability of a random event. Classic definitionevent probability A: The probability of events A is equal to the ratio of the number of cases favored by the event A (M), to the total number of cases (N). Statistical definitionprobability Relative frequency of events- This is the proportion of those actually carried out tests in which the event A appears w \u003d p * (a) \u003d m / n. This is an experimental experimental characteristic, where M is the number of experiments in which an event A appeared; N is the number of all experiments. Probability of eventa number is called the number of which the frequency values \u200b\u200bof this event are grouped in various series of a large number of tests P (a) \u003d. Events are called non-bedsIf the offensive of one of them eliminates the appearance of another. Otherwise event - joint. Sumtwo events are an event in which at least one of these events appears (A or B). If a and in joint Events, then their amount A + B denotes the event of events A or event in, or both events together. If a and in non-stop Events, then the sum A + B means an offensive or event A or Event V. Event is called independent from events A, if the appearance of an event and does not change the probabilities of the appearance of the event. The probability of several independent Events are equal to the product of the probabilities of these: P (AB) \u003d p (a) * p (b) For dependent Events: P (AB) \u003d p (a) * P (b / a). The probability of the work of two events is equal to the product of the likelihood of one of them on the conditional probability of another, found under the assumption that the first event happened. Conditional probability Events B is the probability of event in, found under the condition that the event A happened. Denotes p (in / a) Composition Two events are an event consisting in the joint appearance of these events (A and B) Bayes formula is used to revaluate random events. P (H / A) \u003d (P (H) * P (A / H)) / P (A) P (H) - a priori probability of an event P (H / A) is a posteriori probability of hypothesis H, provided that the event has already happened P (A / H) - expert assessment P (a) - full of the likelihood of event a 3. Distribution of discrete and continuous random variables and their characteristics: mathematical expectation, dispersion, secondary quadratic deviation. Normal law of distribution of continuous random variables. Random value- This is the value that, as a result of the test, depending on the case, takes one of the possible set of its values. Discrete random variability–
this is a random value when accepting a separate isolated, countable set of values. Continuous random amount- This is a random value that takes any values \u200b\u200bfrom some interval. The concept of a continuous random variable occurs during measurements. For discreterandom variance The distribution law can be set as tables, analytically (as a formula) and graphically. Table–
this is the simplest form of assignment of the distribution law. Requirements: for discrete random variables Analytical: 1) f (x) \u003d p (x Distribution function \u003d integral distribution function. For discrete and continuous random variables. 2) f (x) \u003d f '(x) Probability distribution density \u003d Differential distribution function only for continuous random veliver. Graphic: C-VA: 1) 0≤F (x) ≤1 2) inconsistent for discrete random variables C-VA: 1) F (x) ≥0 p (x) \u003d 2) SCIA S \u003d 1 for continuous random variables Characteristics: 1.Mathematical expectation - the average most likely event For discrete random variables. For continuous random variables. 2) Dispersion - scattering around mathematical expectation For discrete random variables: D (x) \u003d x i -m (x)) 2 * p i For continuous random variables: D (x) \u003d x-m (x)) 2 * f (x) dx 3) secondary quadratic deviation: σ (x) \u003d √ (D (x)) σ - standard deviation or standard x - Arithmetic value of square root from its dispersion Normal distribution law (NZR) - Gauss's law NZR is the disintegability of the probabilities of a continuous random variable, which is described by the differential function In practice, most random variables on which a large number of random factors affect the normal law of probability distribution. Therefore, in various applications of probability theory, this law is of particular importance. The random value of $ x $ is subject to the normal law of probability distribution, if its probability distribution density has the following type $$ F \\ left (x \\ right) \u003d ((1) \\ OVER (\\ Sigma \\ sqrt (2 \\ pi))) E ^ (- (((\\ left (xa \\ right)) ^ 2) \\ Over ( 2 (\\ Sigma) ^ 2))) $$ Schematically, the function of the function $ F \\ Left (X \\ Right) $ is shown in the figure and is called "Gaussian curve". To the right of this schedule depicted a banknote in 10 FRG brands, which was used before the emergence of the euro. If you look good, then on this banknote you can see Gaussian curve and its discoverer of the greatest mathematician Karl Friedrich Gauss. Let us return to our density function $ f \\ left (x \\ right) $ and give some explanations regarding the distribution parameters $ a, \\ (\\ sigma) ^ $ 2. The $ a $ parameter characterizes the center of dispersing the values \u200b\u200bof the random variable, that is, it makes sense of mathematical expectation. When the parameter is changed $ a $ and the unchanged parameter $ (\\ Sigma) ^ 2 $, we can observe the schedule of the function $ F \\ left (x \\ right) $ along the abscissa axis, while the density schedule itself does not change its form. The $ parameter (\\ sigma) ^ 2 $ is a dispersion and characterizes the curve shape of the curve of the density of the $ F \\ left (X \\ Right) $. When the parameter is changed $ (\\ Sigma) ^ 2 $ with the unchanged parameter $ a $, we can observe how the density schedule changes its shape, compressing or stretching, while not moving along the abscissa axis. As you know, the likelihood of a random variable of $ x $ to the interval $ \\ left (\\ alpha; \\ \\ beta \\ right) $ can be calculated $ p \\ left (\\ alpha< X < \beta \right)=\int^{\beta }_{\alpha }{f\left(x\right)dx}$. Для нормального распределения случайной величины $X$ с параметрами $a,\ \sigma $ справедлива следующая формула: $$ P \\ left (\\ alpha< X < \beta \right)=\Phi \left({{\beta -a}\over {\sigma }}\right)-\Phi \left({{\alpha -a}\over {\sigma }}\right)$$ Here is the function $ \\ phi \\ left (x \\ right) \u003d ((1) \\ over (\\ sqrt (2 \\ pi))) \\ int ^ x_0 (E ^ (- T ^ 2/2) DT) $ - Laplace function . The values \u200b\u200bof this function are taken from. The following properties of the function $ \\ phi \\ left (x \\ right) $ are noted. 1
. $ \\ Phi \\ left (-x \\ right) \u003d - \\ phi \\ left (x \\ right) $, that is, the $ \\ phi \\ left (x \\ right) $ is odd. 2
. $ \\ Phi \\ left (x \\ right) $ is a monotonously increasing function. 3
. $ (\\ mathop (lim) _ (x \\ to + \\ infty) \\ phi \\ left (x \\ right) \\) \u003d 0.5 $, $ (\\ mathop (Lim) _ (x \\ to - \\ infty) \\ To calculate the values \u200b\u200bof the function $ \\ PHI \\ Left (x \\ right) $, you can also use the Master function $ F_X $ package Excel: $ \\ phi \\ left (x \\ right) \u003d Normarasp \\ left (x; 0; 1; 1 \\ right ) -05 $. For example, we calculate the values \u200b\u200bof the function $ \\ phi \\ left (x \\ right) $ with $ x \u003d $ 2. The probability of entering the normally distributed random variable of $ x \\ in n \\ left (a; \\ (\\ sigma) ^ 2 \\ Right) $ to the interval, symmetric relative to the mathematical expectation of $ A $, can be calculated by the formula $$ P \\ Left (\\ Left | X-A \\ Right | Rule three sigm< \delta \right)=2\Phi \left({{\delta }\over {\sigma }}\right).$$ . It is practically reliably that a normally distributed random value of $ x $ will fall into the interval $ \\ left (A-3 \\ Sigma; A + 3 \\ Sigma \\ Right) $.Example 1. . The random value of $ x $ is subordinate to the normal law of probability distribution with parameters $ a \u003d 2, \\ \\ sigma \u003d $ 3. Find the probability of hitting $ x $ to the interval $ \\ left (0.5; 1 \\ Right) $ and the likelihood of an inequality of $ \\ left | x-a \\ right |
Using the formula< 0,2$. We find $ p \\ left (0.5; 1 \\ right) \u003d \\ phi \\ left ((((1-2) \\ OVER (3)) \\ Right) - \\ phi \\ left (((0.5-2) \\ Left (0.33 \\ RIGHT) \u003d 0.191-0,129 \u003d 0.062 $. $$ P \\ left (\\ alpha< X < \beta \right)=\Phi \left({{\beta -a}\over {\sigma }}\right)-\Phi \left({{\alpha -a}\over {\sigma }}\right),$$ example 2. Rule three sigm< 0,2\right)=2\Phi \left({{\delta }\over {\sigma }}\right)=2\Phi \left({{0,2}\over {3}}\right)=2\Phi \left(0,07\right)=2\cdot 0,028=0,056.$$ . Suppose that during the year the price of shares of some company has a random value, distributed according to a normal law with a mathematical expectation of 50 conditional monetary units, and a standard deviation of 10. What is the likelihood that the price of the period under discussion is randomly selected. The share will be:
a) more than 70 conditional monetary units? b) below 50 per share? c) between 45 and 58 conditional monetary units for the action? let a random variety of $ x $ - the price of shares of some company. By the condition $ x $ is subordinated to the normal law with the distribution with parameters $ a \u003d $ 50 - a mathematical expectation, $ \\ sigma \u003d $ 10 is a standard deviation. The probability of $ p \\ left (\\ alpha $ a) \\ p \\ left (x\u003e 70 \\ right) \u003d \\ phi \\ left (((\\ infty -50) \\ OVER (10)) \\ Right) - \\ phi \\ left (((70-50) \\ $$ b) \\ p \\ left (x< X < \beta \right)$ попадания $X$ в интервал $\left(\alpha ,\ \beta \right)$ будем находить по формуле: $$ P \\ left (\\ alpha< X < \beta \right)=\Phi \left({{\beta -a}\over {\sigma }}\right)-\Phi \left({{\alpha -a}\over {\sigma }}\right).$$ $$ c) \\ p \\ left (45 Binomial distribution is one of the most important probability distributions of a discretely changing random variable.< 50\right)=\Phi \left({{50-50}\over {10}}\right)-\Phi \left({{-\infty -50}\over {10}}\right)=\Phi \left(0\right)+0,5=0+0,5=0,5.$$ The binomial distribution is the distribution of the probability of the number< X < 58\right)=\Phi \left({{58-50}\over {10}}\right)-\Phi \left({{45-50}\over {10}}\right)=\Phi \left(0,8\right)-\Phi \left(-0,5\right)=\Phi \left(0,8\right)+\Phi \left(0,5\right)=$$ M. An occurrence of an event bUT in N. Mutually independent observations . Often event They call the "success" of observation, and the opposite event - "failure", but this designation is very conditional. N. Binomial distribution conditions: The probability that in . Often event Tests Event N. It will come exactly bUT Once, you can calculate according to Bernoulli formula: where p. - probability of event N.; q. = 1 - p. - The likelihood of the opposite event. Let's figure out why the binomial distribution described above is associated with Bernoulli Formula
. Event - the number of success when . Often event Tests disintegrates on a number of options, in each of which success is achieved in bUT Tests, and fail - in . Often event - bUT Tests. Consider one of these options - B.1
. According to the rule of probability, we multiply the probability of opposing events: and if we denote q. = 1 - p. T. The same probability will have any other option in which bUT Successes I. . Often event - bUT failure. The number of such options is the number of methods that can be from . Often event Tests get bUT Successes. The sum of the probabilities of all bUT numbers of events N. (numbers from 0 to . Often event) is equal to one: where every term is the head of Newton's Binoma. Therefore, the distribution under consideration is called binomial distribution. In practice, it is often necessary to calculate the probabilities "no more bUT Successes B. . Often event Tests "or" not less bUT Successes B. . Often event Tests ". For this, the following formulas are used. Integral function, that is probability F.(bUT) what's in . Often event Observations event N. It will come no more bUT time, It can be calculated by the formula: In turn probability F.(≥bUT) what's in . Often event Observations event N. will come no less bUT time, calculated by the formula: Sometimes it is more convenient to calculate the likelihood that in . Often event Observations event N. It will come no more bUT Once, through the likelihood of the opposite event: Which of the formulas to use depends on which one amount contains less than the terms. The characteristics of the binomial distribution are calculated by the following formulas.
. Expected value: . Dispersion :. Rivalthing deviation :. The probability of binomial distribution P.n ( bUT) and the values \u200b\u200bof the integral function F.(bUT) You can calculate using the MS Excel function Binomasp. The window for the appropriate calculation is shown below (to zoom in the left mouse button). MS Excel requires to enter the following data: Example 1.The manager of the firm summarized information on the number of cameras sold over the last 100 days. The table summarizes the information and calculated the likelihoods that a certain number of cameras will be sold per day. The day is completed with the profit if 13 or more cameras are sold. The probability that the day will be worked with profit: The likelihood that the day will be worked without profit: Let the likelihood that the day is worked with profit is constant and equal to 0.61, and the number of cameras sold on the day does not depend on the day. Then you can use a binomial distribution where the event N. - The day will be worked with profit, - without profit. The likelihood that out of 6 days everything will be worked with profit: The same result is obtained using the MS Excel function Binomasp (the value of the integral value is 0): P.6
(6
) \u003d Binom.RP (6; 6; 0.61; 0) \u003d 0.052. The likelihood that out of 6 days 4 and more days will be worked with profit: where Using the MS Excel function Binomasp, we calculate the likelihood that out of 6 days no more than 3 days will be completed with profit (the value of the integral value is 1): P.6
(≤3
) \u003d Binomesp (3; 6; 0.61; 1) \u003d 0.435. The likelihood that out of 6 days everything will be worked out with losses: The same figure is calculated using the MS Excel Binomes function: P.6
(0
) \u003d Binomesp (0; 6; 0.61; 0) \u003d 0.0035. Example 2. In the urn 2 white balls and 3 blacks. The ball takes out the ball, set color and put back. Attempts repeat 5 times. The number of appearance of white balls is a discrete random value X. , Distributed by Binomial Law. Make the law of the distribution of random variable. Determine fashion, mathematical expectation and dispersion. Example 3. From the courier service went to objects . Often event \u003d 5 couriers. Every courier with probability p. \u003d 0.3 Regardless of the others, it is late for an object. Discrete random variability X. - The number of late couriers. Build a number of distribution is a random variable. Find its mathematical expectation, dispersion, secondary quadratic deviation. Find the likelihood that at least two couriers are late for objects. Despite exotic names, common distributions are associated with each other quite intuitive and interesting ways, allowing them to easily remember them and confidently talk about them. Some naturally follow, for example, from the distribution of Bernoulli. Time to show the map of these connections. Each distribution is illustrated by an example of its distribution density function (FPR). This article is only about those distributions whose outcomes are single numbers. Therefore, the horizontal axis of each schedule is a set of possible numbers. Vertical - the likelihood of each outcome. Some distributions are discrete - they have outcomes to be integers, such as 0 or 5. Such are denoted by rare lines, one for each outcome, with a height corresponding to the probability of this outcome. Some are continuous, their outcomes can take any numerical value, type -1.32 or 0.005. These are shown with dense curves with areas under the curve sections that provide probabilities. The amount of heights of lines and regions under curves is always 1. Print, cut off the dotted line and wear with you in the wallet. This is your guide in the country of distributions and their relatives. Bernoulli Distribution can represent and non-equilibrium outcomes, such as an incorrect coin. Then the probability of an eagle will not be 0.5, but some other value P, and the probability of the rush is 1-p. Like many other distributions, this is actually a whole family of distributions specified by certain parameters as P above. When you think "Bernoulli" - think about the "throw (possibly wrong) coin." From here a very small step before presenting the distribution over several equivalent outcomes: a uniform distribution characterized by flat FPR. Imagine the right playing cube. Its outcomes 1-6 are equally even. It can be asked for any number of outs of N, and even in the form of a continuous distribution. Think of a uniform distribution as a "right playing cube". Throw a honest coin two times - how many times will the eagle? This is a submissive binomial distribution. Its parameters - N, the number of tests, and P is the likelihood of "success" (in our case - eagle or 1). Each throw is distributed by Bernoulli outcome, or test. Use the binomial distribution when you consider the number of success in things such as a coin throw, where each throw does not depend on others and has the same probability of success. Or imagine urn with the same amount of white and black balls. Close your eyes, pull out the ball, write down its color and return back. Repeat. How many times did the black ball pulled out? This number is also subject to binomial distribution. We presented this strange situation to make it easier to understand the meaning of hypergeometric distribution. It is the distribution of the same number, but in a situation if we not Returned the balls back. It is definitely a cousin of the binomial distribution, but not the same, since the probability of success changes with each shaded ball. If the number of balls is quite large compared to the amount of pull-out - then these distributions are almost the same, since the chance of success changes with each pulling extremely slightly. When somewhere speak of pulling out the balls from the urn without a return, it is almost always safe to screw "Yes, a hypergeometric distribution", because in life I have not yet met anyone who really fill urns with balls and then pulled them out and returned them, or vice versa. I even have no acquaintances with urns. Even more often, this distribution should emerge when choosing a significant subset of some general population as a sample. Approx. Translate It may not be very clear here, and since the tutorial and the express course for beginners - it would be necessary to clarify. The general population is something that we want to statistically evaluate. To assess, we choose some part (subset) and we produce the required assessment on it (then this subset is called the sample), assuming that the assessment will be similar for the whole set. But that it was true, additional restrictions are often required to determine the subset of the sample (or vice versa, according to a known sample, we need to evaluate whether it describes a fairly preciseness). Practical example - we need to choose from the company in 100 people representatives for a trip to E3. It is known that 10 people have already traveled in her last year (but no one confesses). How many minimum need to take in a group with a high probability of at least one experienced comrade? In this case, the general aggregate is 100, the sample - 10, the selection requirements - at least one, already traveled to E3. Wikipedia has a less fun, but a more practical example about defective parts in the party. Just like the binomial, the distribution of Poisson is the distribution of the quantity: the number of times will happen. It is not parametrized by the probability of p and the number of tests N, but the average intensity λ, which is analogy with the binomial, simply constant NP value. Poisson's distribution - what we need Remember when we are talking about counting events for a certain time with a constant specified intensity. When there is something, like the arrival of the packages on the router or the appearance of buyers in the store or something waiting in the queue - think "Poisson". If the binomial distribution is "how many success", then the geometric is "how many failures before success?". Negative binomial distribution - simple generalization of the previous one. This is the number of failures before R, not 1, success. Therefore, it is additionally parameterized by this R. Sometimes it is described as the number of success to R failure. But, as my life-coach says: "You yourself decide that there is a success, but what is a failure," so this is the same, if you do not forget that the probability P should also be the correct probability of success or failure, respectively. If you need a joke for removing the voltage, it can be mentioned that the binomial and hypergeometric distribution is an obvious steam, but also a geometric and negative binomial is as very similar, after which they say "Well, who does all them call them, eh?" Well, as before, we turn in the geometric distribution to the limit relative to the time fraction - and voila. We get an exponential distribution that accurately describes the time before the call. This is a continuous distribution, the first is from us, because the outcome is not necessarily in the whole seconds. As well as the distribution of Poisson, it is parametrized by the intensity λ. Repeating the binomial connection with geometric, Poisson "How many events during the time?" is associated with exponential "how much before the event?" If there are events, the number of which per unit of time is obeyed by the distribution of Poisson, the time between them is subject to the exponential distribution with the same parameter λ. This correspondence between two distributions must be noted when any of them is discussed. The exponential distribution must come to mind when reflected on the "time to the event", perhaps "time to failure." In fact, this is such an important situation that there are more generalized distributions to describe the development-on-failure, such as Wibul distribution. While the exponential distribution is suitable when the intensity - wear, or failures, for example, is constant, the Wübul distribution can simulate the increasing (or decreasing) failure intensity. Exponential, in general, a special case. Think of "Weibul" when the conversation comes to developing-on-failure. Approx. Translate I was surprised that the author does not write about the need for a comparable scale of summed distributions: if one thing significantly dominates the rest - it will be extremely bad. And, in general, absolute mutual independence is optional, a weak dependence is sufficient. Well, it will come, probably for parties, as he wrote. In its context, the normal is associated with all distributions. Although, basically, it is associated with the distribution of all amounts. Bernoulli test sum follows binomial distribution and, with an increase in the number of tests, this binomial distribution is becoming closer in normal distribution. Similarly, his cousin is a hypergeometric distribution. Poisson's distribution is the limit form of binomial - the same approaches normal with an increase in the intensity parameter. The outcomes that are subject to the logon distribution give values \u200b\u200bthat are normally distributed normally. Or in a different way: the exhibitor is normalized normally distributed. If the sums are normally distributed, then remember the same way that the works are distributed slightly. the T-distribution of Student is the basis of the T test, which many nonstatistics are studied in other areas. It is used for assumptions about the average normal distribution and also tends to normal distribution with an increase in its parameter. A distinctive feature of the T-distribution is its tails, which is thicker than normal distribution. If the thickness joke has not enough for your neighbor, go in a rather funny bike about beer. More than 100 years ago, Guinness used statistics to improve his stout. Then William Sili Sili and invented a fully new statistical theory for improved barley cultivation. Gosset convinced the boss that other brewers would not understand how to use his ideas, and received permission to publish, but under the pseudonym "Student". The most famous achievement of the Gosset is just the most T-distribution, which, one can say, is named after him. Finally, the distribution of chi-square is the distribution of the sums of squares of normally distributed values. In this distribution, a chi-square test was built, which is based on the sum of squares of differences, which should be normally distributed. Do not join the conversation about these conjugated distributions, but if you still have, do not forget to say about beta distribution, because it is a conjugate a priori to most of the distributions mentioned here. Data-Scientist-s are confident that it is for this and done. Mention about this with nonarark and go to the door.






T has an exponential distribution with a parameter (lambda). Exponential distribution is often used to describe the intervals between consistent random events, for example, intervals between currently unproofing site, as these visits are rare events.![]()




![]()





























![]()

![]()
![]()







![]() does not exceed the dispersion of the binomial distribution NPQ. At the moments of any order of hypergeometric distribution, they strive for the corresponding values \u200b\u200bof the moments of the binomial distribution.
does not exceed the dispersion of the binomial distribution NPQ. At the moments of any order of hypergeometric distribution, they strive for the corresponding values \u200b\u200bof the moments of the binomial distribution.



![]() will have the distribution of the relay.
will have the distribution of the relay.


![]()




















![]() It has the distribution of Maxwell. Thus, the distribution of Maxwell can be considered as the distribution of the random vector length, the coordinates of which in the Cartesian coordinate system in the three-dimensional space are independent and normally distributed with mean 0 and dispersion õ 2.
It has the distribution of Maxwell. Thus, the distribution of Maxwell can be considered as the distribution of the random vector length, the coordinates of which in the Cartesian coordinate system in the three-dimensional space are independent and normally distributed with mean 0 and dispersion õ 2.
![]()




![]() And put
And put




2. The concept of dependent and independent events. The conditional probability, the law (theorem) of the multiplication of probabilities. Bayes formula.





The probability of entering a normally distributed random variable in a given interval


![]()
![]() ,
,![]() ,
,![]() .
.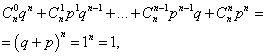
![]() .
.Binomial distribution and calculations in MS Excel

![]()
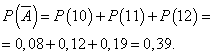
![]() .
.![]() ,
,![]() ,
,![]() ,
,Solve the task yourself, and then see the decision
We continue to solve problems together
Bernoulli and uniform
You have already met with the distribution of Bernoulli above, with two outcomes - an eagle or a wide. Imagine it now as the distribution over 0 and 1, 0 - Eagle, 1 - Rush. As already clearly, both outcome is equally, and this is reflected in the diagram. FPR Bernoulli contains two lines of the same height, representing 2 equivalent outgoings: 0 and 1, respectively. Binomial and hypergeometric
The binomial distribution can be represented as the sum of the outcomes of those things that follow the distribution of Bernoulli. Poisson
What about the number of customers calling on the hotline in technical support every minute? This is the outcome, whose distribution at first glance is binomial, if you consider every second as a test of Bernoulli, during which the customer will not call (0), or call (1). But the power supplying organizations know perfectly well: when electricity is turned off - two can call in second or even more hundreds of people. To present it as 60,000 millisecond tests will also not help - the tests are larger, the probability of a call to the millisecond is less, even if you do not take into account two and more simultaneously, but technically is still not a test of Bernoulli. Nevertheless, a logical reasoning is triggered with the transition to infinity. Let N strive to infinity, and P to 0, and so that NP is constant. This is how to share on increasingly small share of time with a less low probability of a call. In the limit, we get the distribution of Poisson. Geometric and negative binomial
From simple tests of Bernoulli, another distribution appears. How many times the coin falls down with a wide, before falling out an eagle? The number of grills is subject to geometric distribution. Like the distribution of Bernoulli, it is parametrized by the probability of successful outcome, p. It is not parametrized by the number n, the number of tests of tests, because the number of unsuccessful tests is just an outcome. Exponential and Weibula
Again about calls to technical support: how much will it go until the next call? The distribution of this waiting time as if geometric, because each second, until no one calls - it's like fail, until a second, until finally, the call will not happen. The number of failures is like a number of seconds, until no one called, and it practically Time until the next call, but "practically" we are not enough for us. The bottom line is that this time will be the sum of the whole seconds, and thus it will not be possible to calculate the waiting inside this second until the call directly. Normal, Lognormal, Student and Chi-Square
Normal, or Gaussian, distribution, probably one of the most important. His bell-shaped form is recognized immediately. As, this is a particularly curious essence, which is manifested everywhere, even from the externally simplest sources. Take a set of values \u200b\u200bsubject to one distribution - anyone! - And fold them. The distribution of their sum obeys (approximately) to normal distribution. The more things are summed up - the closer their sum corresponds to the normal distribution (catching: the distribution of the components should be predictable, to be independent, it seeks only to normal). The fact that it is so despite the original distribution is amazing.
This is called the "Central Limit Theorem", and it is necessary to know that this is why it is so named and what means, otherwise you immediately marry. Gamma and Beta
In this place, if you have already started talking about something chi-square, the conversation begins to seriously. You are already perhaps talking to real statistics, and, probably, it is worth out to be outlawed, since things like gamma distribution type can emerge. This is a generalization and exponential and Chi-square distribution. Like an exponential distribution, it is used for complex models of waiting times. For example, the gamma distribution appears when the time is simulated to the following N events. It appears in machine learning as a "conjugate a priori distribution" to a couple of other distributions. Beginning of wisdom
The probability distribution is what you can not know too much. At this particular concerned can appeal to this super-talisated map of all probability distributions Add Tags
"The woman is created for a man, not a man for a woman" - such a postulate ...

How is HIV on different time segments manifest? The reasons for the development of AIDS is ...

Stomach Cancer: Symptoms, Causes, Treatment of Stomach Cancer is a change in cell type ...